Automated Image Analysis: The power of Convolutional Neural Networks
What is image analysis?
Image analysis is the process of extracting meaningful information from images. The type and amount of information depends on the context and application. For example, the Eyecon2 particle-size analyser contains an automated image-analysis component that is designed to measure attributes of every particle in an image. Figure 1 shows an example image of coated sphere particles
The process of automated image analysis can be broken down into two major tasks. A vision task, which involves “looking at” the image in order to extract necessary visual information, and a measurement task which takes the extracted visual information and measures attributes required by the application. The measurement task is generally well-defined and involves little to no complexity compared to the vision task which is challenging since it involves emulating human vision. The rest of this article focuses on the vision task alone.
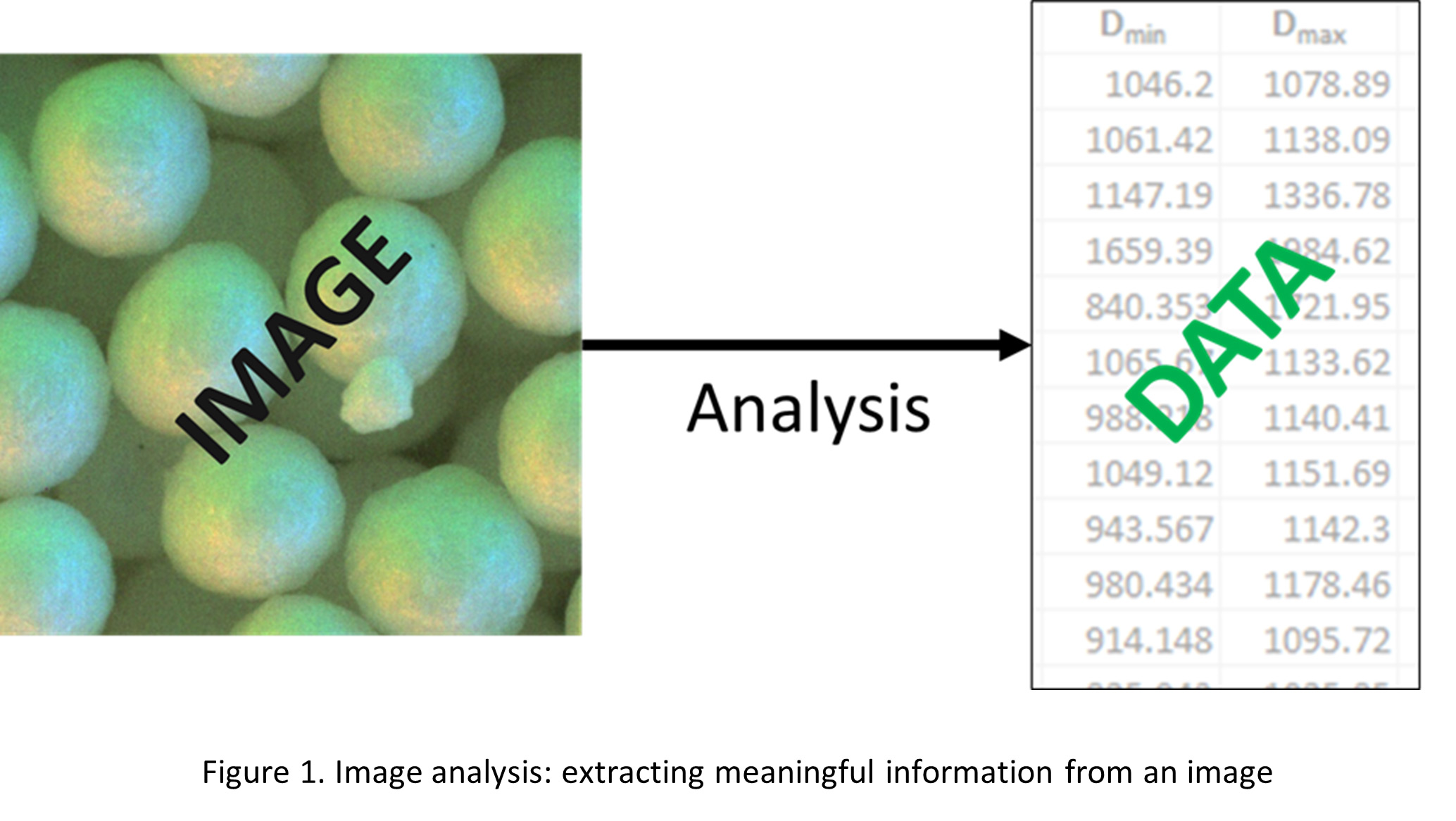
Image Segmentation
In our particle image analysis example, the goal is to get measurements (e.g., d-values) of each particle in the image. To do this, the vision task to be performed is that of locating and delineating every particle in the image. In computer vision jargon, this is called image segmentation. It involves partitioning an image into multiple segments where each segment represents a set of pixels that belong together based on some property. In our example, every particle is a segment. The background is also a separate segment, but is not of interest and usually ignored. Figure 2 shows the expected image segmentation output for our example. This expectation is defined by a human expert by manually drawing around each particle of interest in the image.

Classical Image Processing
The development of automated image segmentation techniques started more than 50 years ago. Until about a decade ago, segmentation was achieved mainly using image processing techniques by designing a pipeline of explicit rules specific to an application. Even today, a lot of applications use such “hand-designed” techniques. A typical automated pipeline consists of three broad steps: (a) pre-processing, e.g., noise removal, (b) segmentation, and (c) post-processing e.g., connected components labelling.
Many kinds of segmentation techniques have been developed over the years. The simplest one is thresholding, which labels each pixel in an image as belonging to either the foreground or background depending on the pixel’s value. Another well-known technique is the watershed algorithm which works by viewing the image as a topographic map. Figures 3 and 4 show the results of these two techniques applied to our example to delineate particles. Note that no pre-processing has been performed in these examples; it is possible to get improved results by appropriate pre-processing. Some amount of clean-up post-processing is also usually required to mitigate issues like false detections and noisy edges.
Designing all three steps of the pipeline to get good results for a specific application involves a lot of effort and experimentation.


Machine learning
Image segmentation can also be performed using machine learning techniques where the goal is to perform the segmentation by learning patterns from the pixel data.
Unsupervised machine learning techniques learn from data without requiring examples of expected input-output pairs (aka training data) e.g., k-means clustering is a method using which pixels with similar characteristics can be grouped together as belonging to a particular segment. Figure 5 shows its application on our example.

In contrast, supervised techniques have to be first trained by providing a curated training dataset: pairs of input images-output labels, before they can be used in an application. The state-of-the-art supervised technique for segmentation is deep learning, specifically, convolutional neural networks (CNNs). These networks are first trained on a set of labelled images that are representative of the images that the solution will need to be able to analyse. Figure 6 shows a few samples from the kind of training dataset that will be required for our example.

Once trained on a representative dataset, a “model” is generated which maps the input images to the output segmentations. This model can then be used to segment new images. Figure 7 shows the result on our original example image.

Classical Image Processing vs CNN
It can be clearly seen from our example that the segmentation results (Figure 7) from a trained CNN are far superior to the ones generated using classical image processing techniques (Figure 3, and Figure 4), and clustering (Figure 5). The CNN outputs closely match the expected segmentation (Figure 2) – all particles are clearly separated from each other, including one smaller particle that partially occludes a bigger one, and there are no false positives detected. This has been achieved without any pre-processing or post-processing steps, but by simply training the network on a well-prepared representative dataset. Also, in CNN-based methods, the number of parameters that need to be adjusted by the user is very small (if not none), whereas classical methods have a bunch of parameters that need to be tuned in order to get acceptable results.
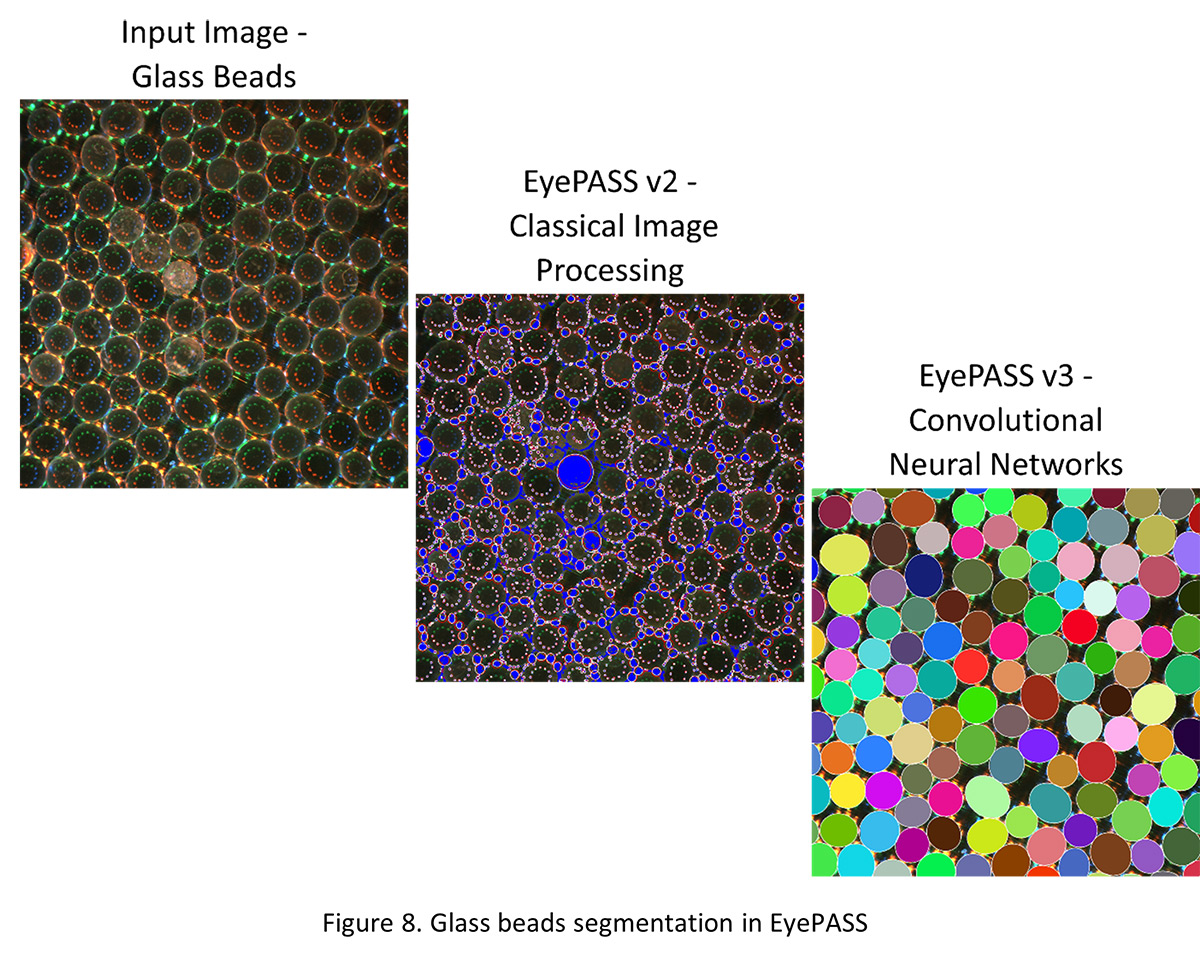
The superior performance is the main advantage of using CNNs, and the reason they are state-of-the-art in not only segmentation problems, but also in other areas of computer vision. The use of CNNs in EyePASS v3 has not only improved the segmentation of particles like coated spheres from our example above, but, as Figure 8 shows, it has also enabled the use of Eyecon2 for measuring more challenging particles including highly reflective ones like glass beads.
Utilise Automated Image Analysis Today
Get in touch with our team today to discuss your needs and see what automated image analysis and artificial intelligence can do for your business.
